
Key Takeaways
- A useful GraphRAG project starts with one specific AI use case, not an enterprise-wide graph ambition.
- The first production step after a demo is a minimum viable graph: the smallest useful set of entities, relationships, evidence, and service contracts.
- Oracle AI Database 26ai is a good fit when you want relational data, vector search, SQL property graphs, and application metadata in one database workflow.
- Treat the graph as a service layer for assistants, applications, analysts, and review workflows, not just as a retrieval trick.
In the first article, we built the mechanics of GraphRAG with Oracle AI Database 26ai. We parsed documents, created chunks, extracted entities and relationships, stored embeddings in VECTOR columns, defined a SQL property graph, and compared baseline vector search with graph-aware retrieval.
That is the right first milestone. You need to see the moving parts work.
The next question is different:
How do we turn this into an AI system that a team can actually use, evaluate, and grow?
That is where many graph projects get into trouble. It is tempting to say, “let’s build the enterprise knowledge graph”, then spend months arguing about the perfect ontology, the perfect taxonomy, and the perfect model of everything. That sounds serious, but it usually puts value too far away from the people who need it.
For AI systems, I prefer a smaller starting point: build a minimum viable graph for one useful capability.
Pick one bounded use case. Model only the entities and relationships needed for that use case. Store every relationship with evidence. Publish a few simple knowledge services over the graph. Then let the graph grow because people are using it, not because the diagram looked complete.
In this follow-up, we will take the GraphRAG schema from article 1 and reshape it into a practical Oracle pattern for AI systems:
- a minimum viable ontology;
- a minimum viable graph;
- a few SQL views and queries that act like knowledge services;
- a small context pack that an LLM or agent can use safely;
- a review loop so extracted relationships improve over time.
This is less about a bigger demo and more about making the demo useful.
Start With The Question The System Should Answer
The graph should not start with “all customer data”, “all product data”, or “all documents”. That is too big to reason about and too easy to turn into a migration project.
Start with a question someone already cares about.
For example:
Which service reports explain why this asset failed, which parts were involved,
and which previous incidents look similar?
That one question gives us a useful first domain:
- assets;
- parts;
- failure events;
- service reports;
- technicians or teams;
- symptoms;
- causes;
- fixes;
- supporting evidence.
Now the graph has a job. It is not just connecting data. It is helping an AI assistant retrieve the right evidence, explain why documents are related, and show the path from a user question to source material.
The same pattern works in other domains:
- contract review: contracts, clauses, regulations, jurisdictions, obligations;
- support: customers, products, incidents, fixes, known issues;
- sales enablement: accounts, industries, products, buying signals, case studies;
- workforce planning: people, skills, projects, learning content, roles.
The important move is to choose one domain where relationship-aware retrieval matters. If plain vector search already answers the question well, keep it simple. GraphRAG is most useful when the answer depends on entities, relationships, paths, provenance, or several pieces of evidence that live in different places.
The Minimum Viable Graph Loop
Here is the loop I like for a first Oracle GraphRAG system.
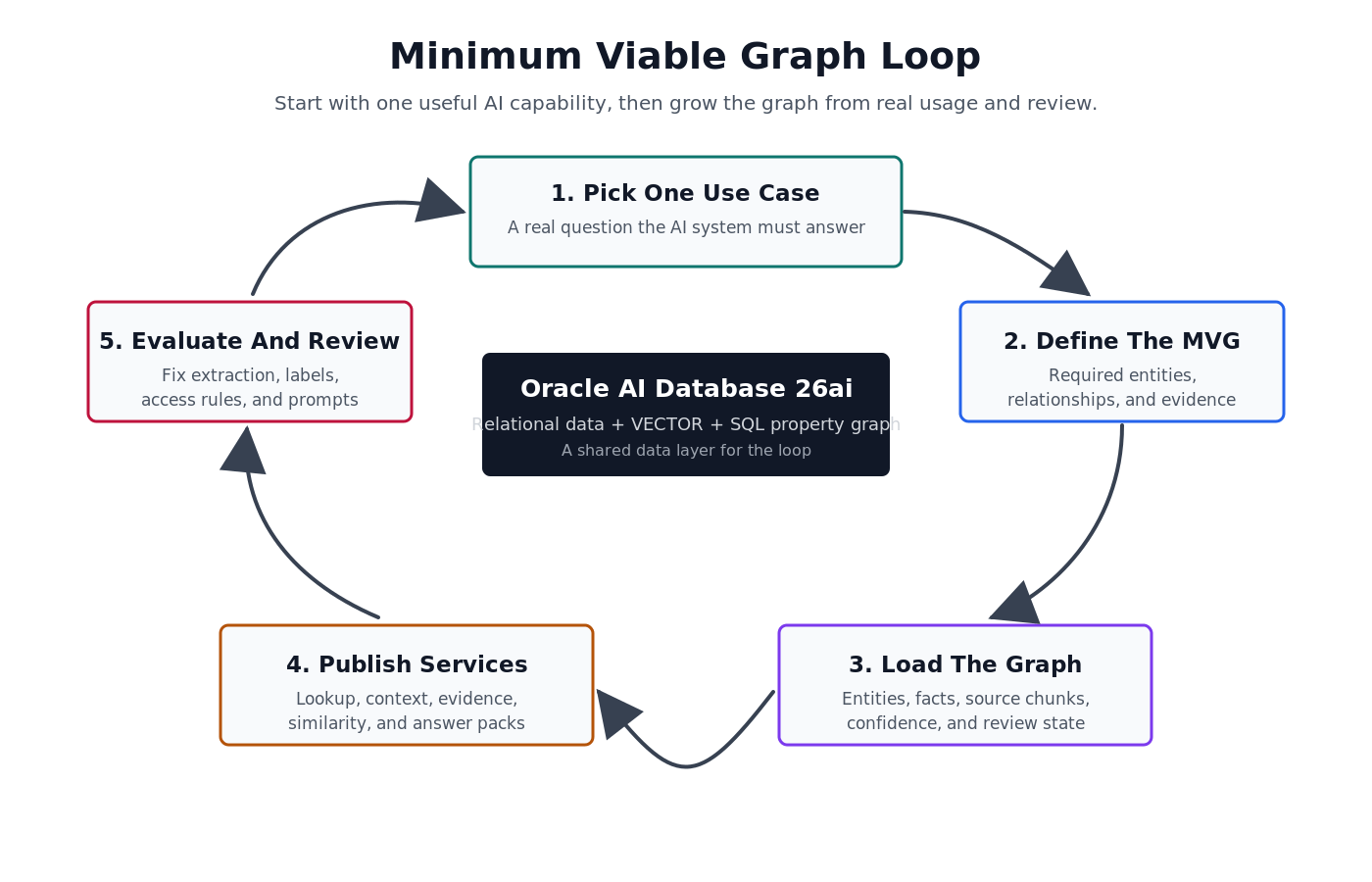
The loop is deliberately small:
- Pick one AI use case.
- Define the minimum viable graph scope and the small ontology it needs.
- Extract and load the minimum viable graph.
- Publish knowledge services.
- Evaluate answers and fix the graph.
The ontology is the vocabulary: entity types, relationship types, and rules. The graph is the instance data: this asset, this part, this service report, this failure event, this evidence.
Keep both small at first. A minimum viable ontology is not the final semantic model for the company. It is the smallest model that lets the use case work. A minimum viable graph is not every record in every system. It is the smallest connected set of evidence that lets a user get a useful answer.
That distinction matters because GraphRAG systems have two quality problems:
- retrieval quality, which determines whether the assistant sees useful evidence;
- graph quality, which determines whether the entity and relationship layer is trustworthy.
You can improve both only if the first graph is small enough to inspect.
Why Oracle Fits This Pattern
In article 1, Oracle AI Database 26ai was the database for chunks, embeddings, extracted entities, relationships, and the SQL property graph. That architecture is useful beyond the tutorial because it keeps several parts of the AI system close together:
- source records and application data in relational tables;
- document chunks and evidence text;
- embeddings in
VECTORcolumns; - vector ranking with
VECTOR_DISTANCE; - extracted entities and relationships;
- SQL property graph metadata with
CREATE PROPERTY GRAPH; - graph pattern queries with
GRAPH_TABLE; - ordinary SQL views for application-facing services.
That last point is easy to underplay. A graph is valuable only when other parts of the system can use it. SQL views, stored procedures, REST endpoints, and application queries are the bridge between “we have a graph” and “the assistant can answer better questions.”
Useful source anchors:
- Oracle AI Database 26ai documentation: https://docs.oracle.com/en/database/oracle/oracle-database/26/
VECTORdata type: https://docs.oracle.com/en/database/oracle/oracle-database/26/vecse/create-tables-using-vector-data-type.htmlVECTOR_DISTANCE: https://docs.oracle.com/en/database/oracle/oracle-database/26/vecse/vector_distance.htmlCREATE PROPERTY GRAPH: https://docs.oracle.com/en/database/oracle/oracle-database/26/sqlrf/create-property-graph.html- Graph reference for
GRAPH_TABLE: https://docs.oracle.com/en/database/oracle/oracle-database/26/sqlrf/graph-reference.html - python-oracledb vector support: https://python-oracledb.readthedocs.io/en/latest/user_guide/vector_data_type.html
The key idea is not that every AI system needs every feature at once. It is that Oracle lets you keep the relational model, vector model, and graph model in one place while you decide which retrieval path the use case actually needs.
Add A Tiny Ontology Layer
The first article used these core tables:
documentschunksentitiesentity_mentionsrelationshipschunk_embeddings
For a more durable AI system, add a small ontology layer. This lets you control which entity and relationship types are allowed, which ones are active, and which ones need review.
CREATE TABLE kg_entity_types ( entity_type VARCHAR2(64) PRIMARY KEY, description VARCHAR2(1000), active_flag CHAR(1) DEFAULT 'Y' CHECK (active_flag IN ('Y', 'N')));CREATE TABLE kg_relationship_types ( relationship_type VARCHAR2(100) PRIMARY KEY, description VARCHAR2(1000), source_entity_type VARCHAR2(64), target_entity_type VARCHAR2(64), active_flag CHAR(1) DEFAULT 'Y' CHECK (active_flag IN ('Y', 'N')), CONSTRAINT kg_rel_source_fk FOREIGN KEY (source_entity_type) REFERENCES kg_entity_types(entity_type), CONSTRAINT kg_rel_target_fk FOREIGN KEY (target_entity_type) REFERENCES kg_entity_types(entity_type));
Then seed only the terms the first use case needs.
INSERT INTO kg_entity_types (entity_type, description) VALUES ('ASSET', 'A physical or logical asset involved in an operational event');INSERT INTO kg_entity_types (entity_type, description) VALUES ('PART', 'A component, material, or replaceable item');INSERT INTO kg_entity_types (entity_type, description) VALUES ('FAILURE_EVENT', 'An observed failure, incident, outage, or service event');INSERT INTO kg_entity_types (entity_type, description) VALUES ('SERVICE_REPORT', 'A document or record that describes service activity');INSERT INTO kg_relationship_types ( relationship_type, description, source_entity_type, target_entity_type) VALUES ( 'INVOLVES', 'Links a failure event or service report to an asset, part, or symptom', 'FAILURE_EVENT', 'PART');
This is not a complete model. That is the point.
The first version should be small enough for a domain expert to say, “yes, those are the relationships we need”, or “no, this relationship should be split into CAUSES, REPLACED_BY, and OBSERVED_IN.”
That conversation is where the graph gets better.
Turn The Graph Into Knowledge Services
The SQL property graph is powerful, but most application code should not need to know the full graph query every time it needs context. Give the rest of the system a few simple services.
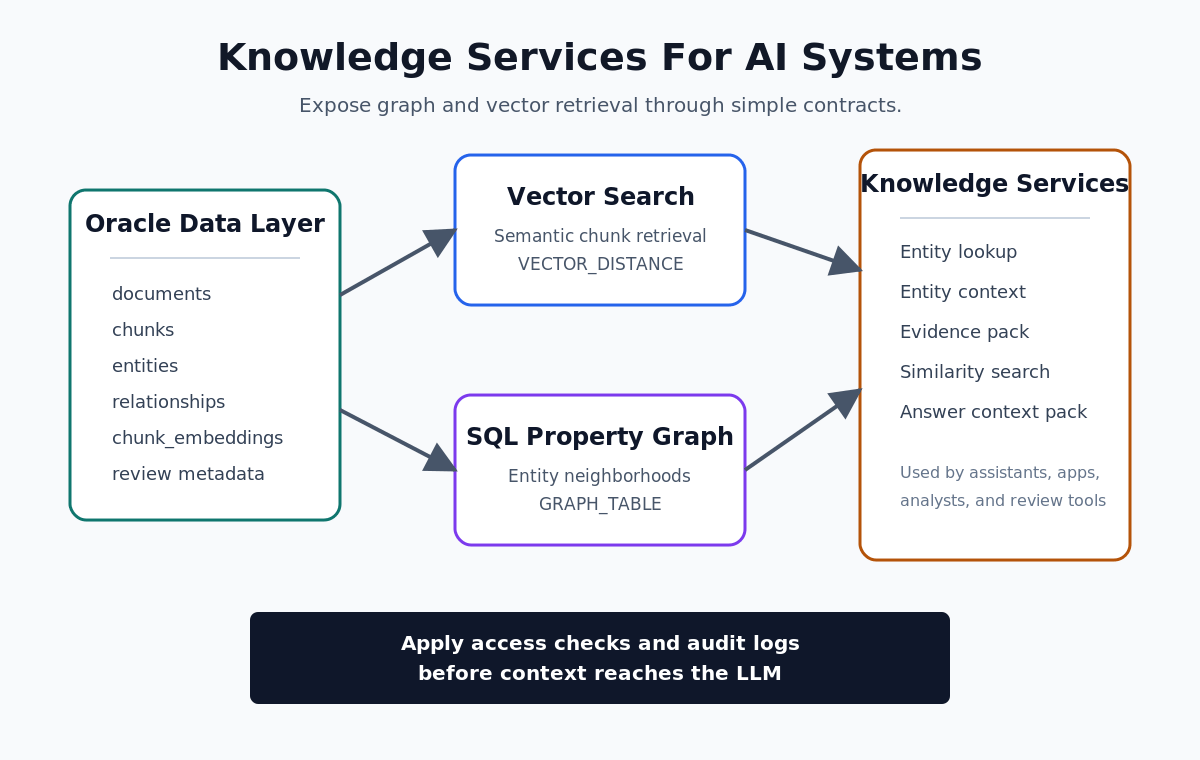
For a first GraphRAG-backed assistant, I would publish five services:
- Entity lookup: find the canonical entity for a user term.
- Entity context: return aliases, types, mentions, and nearby relationships.
- Evidence pack: return source chunks that support a relationship or entity neighborhood.
- Similarity search: return semantically similar chunks with Oracle vector search.
- Answer context pack: combine graph facts and passages into one object for an LLM.
You can expose these as SQL views, PL/SQL functions, ORDS REST endpoints, or application service methods. The transport matters less than the contract.
The assistant should not be asking for “whatever is in the database”. It should be asking for a bounded context pack with evidence.
Demo: Entity Lookup
Start with a plain SQL view that gives applications a stable entity lookup surface.
CREATE OR REPLACE VIEW kg_entity_lookup_v ASSELECT e.entity_id, e.canonical_name, e.entity_type, e.confidence, COUNT(DISTINCT em.chunk_id) AS mention_count, MAX(em.confidence) AS best_mention_confidenceFROM entities eLEFT JOIN entity_mentions em ON em.entity_id = e.entity_idGROUP BY e.entity_id, e.canonical_name, e.entity_type, e.confidence;
Now an application can resolve a user phrase before it tries graph traversal.
SELECT entity_id, canonical_name, entity_type, mention_countFROM kg_entity_lookup_vWHERE LOWER(canonical_name) LIKE LOWER('%pump%')ORDER BY mention_count DESCFETCH FIRST 10 ROWS ONLY;
This looks ordinary, and that is good. Not every part of a GraphRAG application needs to look exotic. A lot of the value comes from making the graph available through boring, dependable interfaces.
Demo: One-Hop Graph Context
Once the entity is resolved, use the SQL property graph to collect nearby facts.
This assumes the property graph from article 1, where entities are vertices and extracted relationships are edges. Adapt the property names to match your exact graph DDL.
SELECT gt.source_entity_id, gt.source_name, gt.relationship_type, gt.target_entity_id, gt.target_name, gt.evidence_chunk_id, gt.confidenceFROM GRAPH_TABLE ( graphrag_entity_graph MATCH (src)-[rel]->(dst) WHERE src.entity_id = :entity_id COLUMNS ( src.entity_id AS source_entity_id, src.canonical_name AS source_name, rel.relationship_type AS relationship_type, dst.entity_id AS target_entity_id, dst.canonical_name AS target_name, rel.evidence_chunk_id AS evidence_chunk_id, rel.confidence AS confidence )) gtORDER BY gt.confidence DESC NULLS LASTFETCH FIRST 20 ROWS ONLY;
For relationship-heavy questions, this is the part plain vector search does not give you directly. The result is not just a passage that sounds related. It is a set of explicit facts with source evidence IDs.
Do not treat those facts as perfect. Treat them as extracted candidates with provenance. The assistant can use them, but the system should still keep evidence chunks close by.
Demo: Evidence Pack
The evidence pack joins graph facts back to chunks. This gives the LLM the two things it needs:
- a compact relationship statement;
- the source text that supports it.
WITH graph_facts AS ( SELECT gt.relationship_type, gt.target_name, gt.evidence_chunk_id, gt.confidence FROM GRAPH_TABLE ( graphrag_entity_graph MATCH (src)-[rel]->(dst) WHERE src.entity_id = :entity_id COLUMNS ( rel.relationship_type AS relationship_type, dst.canonical_name AS target_name, rel.evidence_chunk_id AS evidence_chunk_id, rel.confidence AS confidence ) ) gt)SELECT gf.relationship_type, gf.target_name, gf.confidence, c.chunk_id, d.title, c.section_title, DBMS_LOB.SUBSTR(c.chunk_text, 1200, 1) AS evidence_excerptFROM graph_facts gfJOIN chunks c ON c.chunk_id = gf.evidence_chunk_idJOIN documents d ON d.document_id = c.document_idORDER BY gf.confidence DESC NULLS LASTFETCH FIRST 10 ROWS ONLY;
That is the first service I would put behind an assistant.
Given an entity, return the relationships the system knows about and the evidence that supports them. If this service is weak, the rest of the assistant will be weak too.
Demo: Add Vector Search Back In
Graph retrieval and vector retrieval solve different parts of the problem.
The graph is good at “what is connected to this?” Vector search is good at “what text is semantically close to this question?” For most useful assistants, you want both.
SELECT c.chunk_id, d.title, c.section_title, VECTOR_DISTANCE(e.embedding, :query_embedding, COSINE) AS distance, DBMS_LOB.SUBSTR(c.chunk_text, 1200, 1) AS chunk_excerptFROM chunk_embeddings eJOIN chunks c ON c.chunk_id = e.chunk_idJOIN documents d ON d.document_id = c.document_idWHERE e.embedding_kind = 'RAW'ORDER BY VECTOR_DISTANCE(e.embedding, :query_embedding, COSINE)FETCH FIRST 10 ROWS ONLY;
Now you can build a context pack from two sources:
- graph facts and evidence chunks around matched entities;
- semantically similar chunks from vector search.
Keep the scores visible. If the answer is based mostly on weak graph extraction, the UI or review log should show that. If the answer is based mostly on vector search with no graph support, show that too.
Demo: Build A Context Pack For An LLM
The context pack is the handoff between retrieval and generation.
I like to keep it boring and explicit. Here is a small Python shape:
from dataclasses import dataclassdataclassclass GraphFact: relationship_type: str target_name: str confidence: float | None evidence_chunk_id: int evidence_excerpt: strdataclassclass RetrievedPassage: chunk_id: int title: str distance: float chunk_excerpt: strdataclassclass AnswerContextPack: question: str matched_entity: str graph_facts: list[GraphFact] vector_passages: list[RetrievedPassage]
Then make the prompt rules just as explicit:
Answer the user's question using only the graph facts and passages provided.If the graph facts and passages disagree, explain the disagreement.If the evidence is not enough, say what is missing.For each important claim, include the source chunk ID.Do not invent relationships that are not present in the context pack.
This is the part where GraphRAG becomes more than retrieval. You are giving the model a small evidence workspace with relationship facts, source passages, and instructions about uncertainty.
The LLM still matters. But the database is doing real work before the LLM ever sees the prompt.
What To Evaluate
Do not start by asking whether the graph is “good”. That is too vague.
Evaluate the services.
For a first pass, make a small spreadsheet or table with 20 to 40 questions. Include direct questions, relationship questions, and failure cases.
Useful columns:
- user question;
- expected entity;
- expected relationship type;
- expected source document or chunk;
- baseline vector chunks;
- graph facts returned;
- final context pack;
- answer result;
- reviewer notes.
For each question, ask:
- Did entity lookup resolve the right thing?
- Did graph traversal return useful relationships?
- Did the evidence pack include the source chunk?
- Did vector search add useful passages?
- Did the assistant cite evidence rather than make a leap?
- Was the answer better than baseline vector retrieval alone?
That last question matters. GraphRAG adds moving parts. It should earn its place.
Some questions will not need graph context. Some will expose bad extraction. Some will show that your relationship labels are too broad. That is not a failure. That is the loop working.
A Practical Adoption Pattern
Once the first use case works, do not jump straight to “enterprise-wide”.
Add one adjacent use case.
If you started with service reports and asset failures, the next use case might be parts recommendations or known-issue discovery. That lets you reuse several entity types while adding only a few new relationships.
A practical adoption path looks like this:
- One use case, one domain, one minimum viable graph.
- Two or three knowledge services used by one assistant or application.
- A review queue for low-confidence entities and relationships.
- A small evaluation set owned by the team that cares about the answers.
- A second use case that reuses part of the graph.
- Shared entity resolution and relationship governance as the graph grows.
This is how the graph becomes an asset instead of a side project.
It also creates better conversations with business users. You are not asking them to approve a universal semantic model. You are showing them an assistant that can answer a hard question, then asking which terms and relationships need to be corrected.
That is a much easier conversation to have.
Keep The Human Review Loop Close
Automated extraction is useful, but it is not authority by itself.
In article 1, every relationship carried evidence text, an evidence chunk ID, a confidence score, and an extraction method. Keep that pattern. Then add review status.
ALTER TABLE relationships ADD ( review_status VARCHAR2(30) DEFAULT 'PENDING' CHECK (review_status IN ('PENDING', 'APPROVED', 'REJECTED', 'NEEDS_REVIEW')), reviewed_by VARCHAR2(200), reviewed_at TIMESTAMP, reviewer_note VARCHAR2(1000));
Now your application can route low-confidence or high-impact relationships to a human review queue.
SELECT r.relationship_id, src.canonical_name AS source_name, r.relationship_type, dst.canonical_name AS target_name, r.confidence, DBMS_LOB.SUBSTR(r.evidence_text, 1000, 1) AS evidence_excerptFROM relationships rJOIN entities src ON src.entity_id = r.source_entity_idJOIN entities dst ON dst.entity_id = r.target_entity_idWHERE r.review_status IN ('PENDING', 'NEEDS_REVIEW')ORDER BY r.confidence ASC NULLS FIRSTFETCH FIRST 25 ROWS ONLY;
This is one of the most important differences between a demo and a system. In a demo, extraction errors are annoying. In a system, extraction errors need a place to go.
Security And Governance Are Part Of Retrieval
If your GraphRAG system retrieves sensitive data, security cannot be bolted on after answer generation.
The retrieval layer should respect the same access rules as the application data. If a user cannot see a source document, the assistant should not see chunks from that document either. If a relationship was extracted from restricted evidence, the relationship should not leak that evidence through a graph answer.
At minimum, design for:
- document-level access checks before chunks are retrieved;
- entity and relationship filters for tenant, domain, or sensitivity;
- audit logs for context packs sent to an LLM;
- masking or redaction for sensitive fields;
- separate review flows for high-impact relationships.
The nice thing about keeping this in Oracle is that you can use database-side controls and ordinary application authorization patterns close to the data. The hard part is discipline: apply access rules before building the prompt, not after the model has already seen the evidence.
Where This Leaves Us
Article 1 built the GraphRAG machinery. This article turns that machinery into a pattern a team can operate:
- start with one relationship-heavy AI use case;
- define the smallest useful ontology;
- load the smallest useful graph;
- expose the graph through knowledge services;
- combine graph facts and vector passages into context packs;
- evaluate the services;
- review and improve the extracted relationships.
That is a more modest goal than building the grand graph of everything. It is also much more likely to survive contact with real users.
Once the first graph-backed assistant is useful, the next graph gets easier. You reuse entity resolution, evidence handling, service contracts, review queues, and evaluation habits. The graph grows because the applications are pulling it forward.
That is the path I would take: build the smallest graph that makes one AI system meaningfully better, prove it with evidence, and then let the next use case earn the next expansion.

You must be logged in to post a comment.