
I don’t believe that AI will take our software engineering jobs, I believe that those of use who embrace AI will see our jobs evolve and those who do not may end up in other jobs.
I want to share one of my experiences in this “brave new world” of writing software with AI. I am doing a lot of software engineering with AI these days, working together as peers. This is not “vibe coding” (I dislike that term) – this is real software engineering with an AI partner.
Most importantly, AI and I worked as a team. We wrote requirements first, we did several review cycles to make sure they were unambiguous and comprehensive. We spent at least two weeks writing tests before we wrote any code. We had over 400 tests covering almost all of the requirements before a line of code was written. We used modern Java features and capabilities, and best practices.
The application is not finished, but it is performing very well, and it is in production. It is not open source, so I cannot share the code with you. But my AI friend and I can share our story (which we wrote together too!).
YAAH (“Yet Another Attribution Helper”) is the fourth implementation of my US Patent 11,971,965 “System and method for determining attribution associated with licensed software code” (with co-inventor Dan Simone). The first implementation was written in Go by a person (me) and then got other contributors and grew in the usual way we are all familiar with until it became easier to write a new one than continue maintaining it.
The second implementation was an experiment in AI assisted coding, in Python, and it never got better than 80% accuracy no matter how hard we tried.
The third implementation was an attempt to create skills that an AI could use to do this work. It did not go well.
This implementation is written in Java, it uses modern Java features like virtual threads, records, pattern matching, and it follows the kinf of acrchitecture you’d more often find in a functional language like Haskell. Most of the work is in pure functions – they have no side effects, they produce the same output for the same input deterministically, no matter how many times you run them (and so can be memoized). And there’s a thin layer around the edge where all the side effects live – reading and writing files, cloning git repositories, and so on.
So it was written together, in partnership, really as equals, with AI assistants. I don’t think the specific choices are as important and the overall experience, but for those who want to know, I used GPT-5.5 with high reasoning as the “developer”, Claude Code (the latest available model at any given time, Sonnet 4.6 at the time of writing) as my “Architect” who performed most of the reviews, and Gemini 3.x (latest available) Pro and/or Flash as my “Product Manager” who performed a higher level review from time to time with a “Product” (with a captial “P”) hat on.
To give you an idea of the size of this application, it has about 15,000 words of requirements, around 36,000 lines of saved review comments and feedback; 28,000 lines of production Java code (in 224 files), 54,000 lines of test code (in 369 files), with a test-to-production ratio of almost 2:1.
A human (me) wrote 95% of the requirements (they were improved by AI over the course of the project as we discovered new edge cases) and AI wrote everything else.
The Problem Was Not Whether AI Could Write Code
I wanted to build something practical: a command-line tool that can generate a third-party attribution report for a source repository.
That sounds simple until you try to do it well. You need the application license, the copyright notices, and the full dependency graph. You need direct dependencies and transitive dependencies. You need to handle Maven, Gradle, Go, npm, Python, and LuaRocks without pretending they all behave the same way.
Then you need evidence for the exact dependency version.
That last word matters. If an application depends on version 1.2.3, the report needs evidence for version 1.2.3. Not the default branch. Not the nearest tag. Not whatever a repository shows today.
This is the kind of project where an AI-generated prototype can look impressive and still be wrong in ways that matter. A missing dependency, a license from the wrong branch, or a dropped copyright notice can make the output less useful.
So the real question became more interesting than “can AI write code?”
Could we use AI to build software with more discipline, not less?
YAAH became my answer to that question.
Start With the Contract
The first useful artifact was not code. It was our requirements document, which we lovingly called REQUIREMENTS.md. And we fully embraced RFC 2119 – if you have never read it, you really SHOULD.
The requirements were deliberately specific. YAAH had to support multiple ecosystems in one repository, collect recursive dependencies, keep uncertain dependencies unless a reliable test-only signal existed, cache source evidence, continue after ordinary dependency failures, and report those failures clearly.
It also had to preserve legal evidence.
That principle shaped the whole project. If a license or copyright notice might matter, prefer to keep it. Later rules can filter false positives, but the first version of the system should not casually throw evidence away.
This is where AI helped in a way that is easy to miss. Instead of jumping straight to implementation, I used AI to review the requirements.
It found contradictions and weak spots. The report format did not fully explain where non-canonical dependency license text belonged. Test-only dependency rules were too vague. Deduplication keys needed to be ecosystem-specific. Source repository lookup needed stronger rules. The architecture wanted pure functions, but the application also needed files, network calls, git operations, caches, and command execution.
That review was not glamorous, but it was one of the most important parts of the project.
Good AI coding starts before code. It starts by making the target hard to misunderstand.
Make the System Easy to Test
The architecture settled into three Maven modules.
yaah-core owns the domain model, workflow logic, evidence collection, report rendering, parsing, and semantic comparison. yaah-cli is the thin command-line entry point. test-util compares generated reports against reference reports.
That split paid for itself many times. The hard behavior lives in the core, while the CLI parses options and invokes the workflow. The comparison utility reuses the same parsing and semantic model instead of inventing its own understanding of the report.
The next design choice was even more important: separate pure logic from boundary work.
Pure logic can normalize dependency identities, compute dedupe keys, merge report blocks, sort output, classify test-only signals, and compare parsed reports. Boundary work reads files, calls package registries, runs Maven or git, fetches source archives, writes output, touches caches, and optionally calls an LLM.
Keeping that boundary explicit made the code easier to test and easier to change. It also made AI collaboration safer. When a bug showed up, we could ask for a fix in a specific component instead of handing the model a giant ball of side effects.
Build a Safety Net First
The first implementation pass was intentionally small.
The project started with the module skeleton, command-line smoke tests, basic domain records, dependency-list rendering, manual license override parsing, run options, and fixture catalog checks.
From there, the test suite grew quickly. There were tests for dependency identity, package URLs, source version selection, repository URL normalization, known license overrides, report parsing, semantic comparison, vulnerability warning ordering, copyright normalization, SPDX matching, and fixture behavior.
That test-first rhythm mattered because the project had too many edge cases for memory alone. The AI could move quickly, but the tests made it accountable.
Every time the implementation learned a new rule, the suite got another guardrail.
The repository eventually grew to hundreds of production and test files. That size is not automatically a virtue. The useful part was the shape of the growth: small services, typed records, focused tests, and visible review notes.
Let Real Fixtures Teach the Tool
The first fixture was toml-1.6.0, a small Go project with no third-party dependencies. It was perfect for proving top-level license and copyright output.
It was not enough.
A real attribution tool needs messy projects, so the fixture set grew. kingpin exercised Go dependency discovery and exact version checkout. httpx exercised Python metadata and multi-license behavior. Spring Boot Admin exercised Maven graphs, parent POMs, and monorepo subdirectories.
Larger fixtures pushed the tool harder. APISIX, external-secrets, SigNoz, LangChain Core, and LlamaIndex-related runs exposed source-resolution, caching, npm, Python archive, and performance behavior that smaller examples could not show.
That is where the project started to feel real.
Real packages do not politely follow your first design. They use vanity import paths. They publish source archives instead of clean git tags. They live inside monorepos. They use package names that do not match repository names. They put licenses in parent directories and code in subdirectories. They include generated files, examples, docs, vendored content, and old reports.
The fixtures forced YAAH to handle those patterns.
They also changed how we tested output. A byte-for-byte golden file would have been brittle, so test-util compares reports semantically. It can ask whether dependency membership changed, whether license sets changed, whether appendix entries changed, whether dependency errors changed, and whether the final error summary changed.
That made the tests much more useful. When a report changed, we did not just see “the file is different.” We saw what kind of meaning changed.
Prefer Evidence Over Silence
One of the best design decisions was to avoid fail-fast behavior for ordinary dependency problems.
If YAAH cannot resolve one dependency’s source repository, that should not destroy the whole report. The dependency should still appear, the error should be attached to that dependency, and the rest of the run should continue.
That design is practical because it gives the reader a useful report and a concrete list of what needs attention. It also makes the tool more honest. A dependency with a source-resolution error is different from a dependency that does not exist.
The same idea appears in the LLM integration.
YAAH can optionally use an LLM to review ambiguous copyright candidates, but only after deterministic filtering has done its work. The default is no LLM. When the LLM is used, the report includes audit lines in the relevant dependency block.
That is the right safety boundary: deterministic code for deterministic work, narrow LLM use where judgment helps, and auditable output when the LLM participates.
Keep the Ideas, Simplify the Mechanism
The original requirements mentioned an agent framework, and early planning used that vocabulary.
Later, we removed the framework mandate.
That was not a retreat. It was a good engineering decision.
The useful ideas stayed: small workflow stages, typed inputs and outputs, pure logic where possible, boundary adapters for side effects, and clear audit behavior. The framework dependency itself did not need to stay.
This is a useful AI-development lesson. The first plan is allowed to be wrong. The point is not to defend it. The point is to preserve the parts that proved useful and simplify the parts that did not.
After that cleanup, the project released its first snapshot and moved into the next phase: making the working system faster and more robust.
Make It Faster Without Losing Determinism
Once YAAH could produce useful reports, large repositories exposed the next problem: run time.
Processing dependencies one at a time is easy to reason about, but it does not feel good on a repository with hundreds or thousands of dependencies.
The performance work started with a plan, not a random thread pool. The rule was clear: parallelize independent dependency work, but keep the final output deterministic.
Report ordering, dependency-list ordering, final errors, license appendix ordering, and stdout behavior all had to stay stable. That led to virtual-thread dependency workers, bounded source scanning, cache cleanup, cache reuse, timing telemetry, and safer source materialization behavior.
The regression reports show why measurement mattered. Large fixtures exposed slow copyright and license evidence stages, and later runs showed much better throughput after scan controls and caching improvements.
The important point is not the exact timing number. The important point is the method: measure the run, make one class of improvement, run the fixtures again, record what changed, and keep the public output stable.
That loop is much better than asking an AI to “optimize this” and hoping for the best.
Use Regression Reports as Project Memory
The best artifact in the project might be the regression sweep process.
A full sweep builds the application, reads the fixture catalog, runs YAAH against the right fixture directories, saves the report and dependency-list outputs, scans for suspicious failures, runs semantic comparisons where reference reports exist, samples dependencies, and checks source evidence.
That is a serious workflow, and it gives AI a concrete job. Instead of “look for bugs,” the instruction becomes a repeatable runbook: run these fixtures, save these outputs, search for these failure patterns, compare these reports, sample dependencies, inspect evidence, and write down what changed.
That process caught real issues.
For example, one sweep found that a Python dependency had a correct MIT license, but the report also picked up generic prose about copyright law as if it were a copyright notice. That is exactly the kind of false positive you can get when the tool starts from a conservative inclusion rule.
The right response was not panic. It was a follow-up rule: tighten notice extraction for generic prose while preserving real legal notices.
That is how the project got better.
What AI Actually Did Well
The AI wrote code, of course, but that was not the most interesting part.
It helped review the spec. It wrote implementation plans. It identified missing tests. It wrote test scaffolding. It reviewed architecture. It made blunt lists of gaps. It ran fixture sweeps. It summarized regression results. It helped turn messy observations into reusable rules.
That is the pattern I would reuse.
Do not treat AI as a single coding step. Treat it as a collaborator that can play several roles if you give it enough context and enough checks.
The repository became that context.
The .ai directory held plans, reviews, and regression notes. Git held the sequence of decisions. Requirements held the contract. Tests held behavior. Fixtures held reality.
That combination made the collaboration durable. When the conversation changed, the project memory remained.
What I Would Recommend
If you want to use AI on a real software project, start with something more concrete than a prompt.
Write the requirements. Ask the AI to critique them. Fix the contradictions. Decide what must be deterministic. Decide where uncertainty is allowed. Write down how failures should appear to the user.
Then build the smallest testable slice.
Use real fixtures as soon as possible because they will teach you what the tidy examples hide. Keep the fixture catalog explicit, especially when a repository has a narrower run directory than its root.
Create a comparison tool if your output is structured. Text diffs are useful, but semantic diffs tell you what kind of behavior changed.
Keep regression instructions in the repo and make them boring enough to run again. A repeatable sweep is more valuable than a heroic one-time debugging session.
Most of all, use AI to make the engineering process more visible. Ask it to plan, but save the plan. Ask it to review, but commit the fixes. Ask it to run regressions, but keep the report. Ask it to generalize edge cases, then test the general rule.
That is where the leverage is.
Here’s a diagram that outlines the process that I am using more often than not with my AI team:
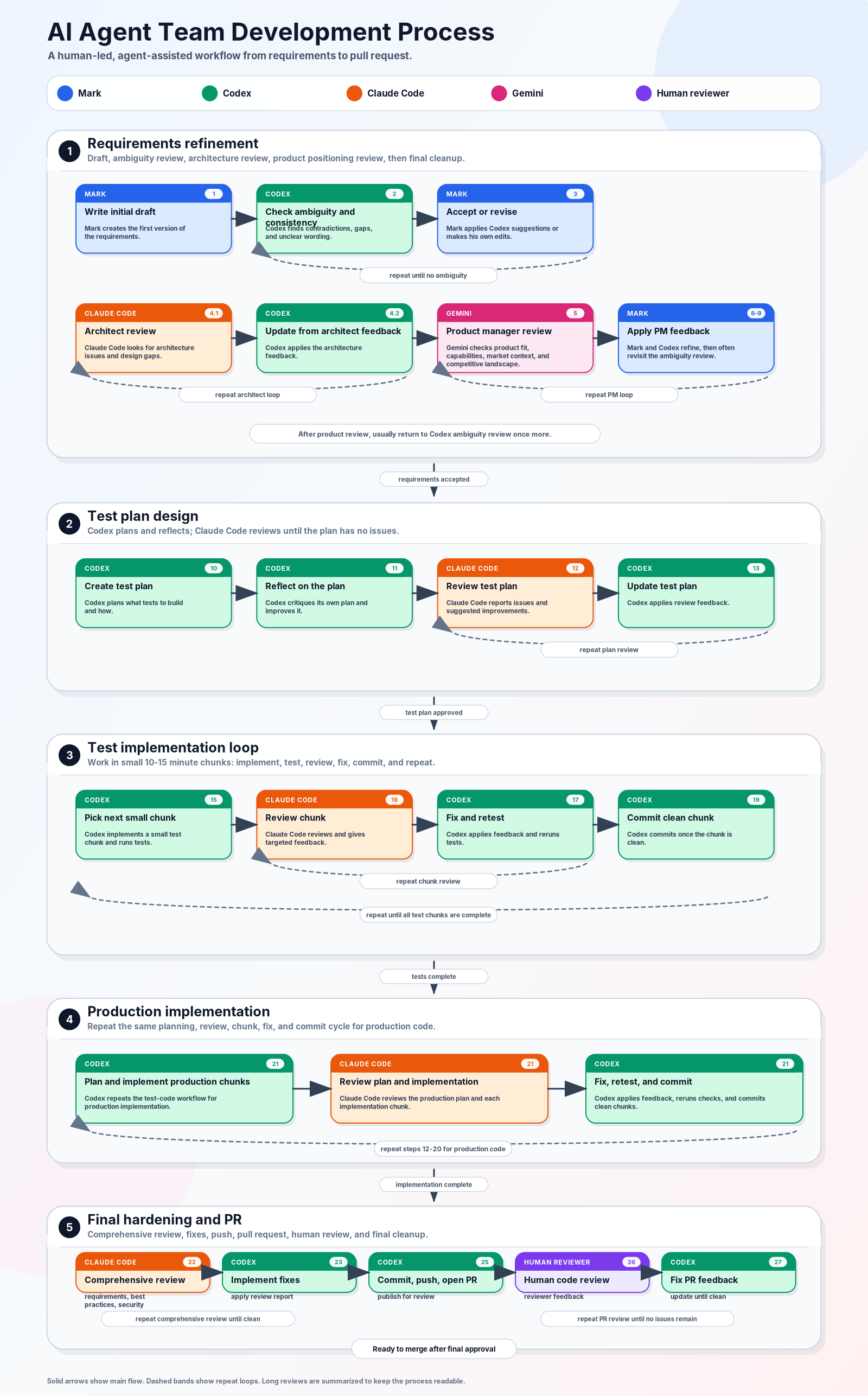
The Result
YAAH is now a real attribution helper, not just a demo.
It can detect several ecosystems, build dependency lists, resolve source repositories, select exact versions, collect license and copyright evidence, use caches, generate attribution reports, write dependency-list output, compare reports semantically, and run broad fixture regressions.
It still has work to do. Attribution tools always do. New package metadata shapes, source archive patterns, license oddities, and false-positive notices will keep showing up.
But the project has the right kind of foundation.
It has a contract. It has tests. It has fixtures. It has regression sweeps. It has review notes. It has a habit of turning surprises into rules.
That is the success story.
AI did not replace engineering discipline here. It helped us practice it more often.
There you go.

Pingback: A Tale of Two Agents: Why we can’t go past CrewAI | RedStack