
Key Takeaways
GraphRAG helps when enterprise answers depend on relationships, not just similar text. A passage can mention the right product or policy and still be wrong for the customer, asset, contract, region, date, entitlement, or user.
Start with a minimum viable knowledge graph. Model the smallest set of entities, relationships, and linked sources that improves one real retrieval workflow before expanding into a broader enterprise graph.
Oracle AI Database 26ai can support a database-centered GraphRAG pattern. SQL property graphs, Oracle AI Vector Search, relational tables, JSON metadata, and SQL predicates can work together while the application or retrieval service orchestrates the workflow.
The useful output is an evidence bundle. A practical GraphRAG system should return passages, graph paths, structured facts, source identifiers, provenance, and authorization-filtered context that an AI application can use safely.
A useful AI answer needs more than similar text
A support engineer asks what sounds like a straightforward question:
Which maintenance policy applies to ACME’s pump 17 after the seal failure?
A vector search workflow may get close. It might retrieve a product manual for Pump X9, a support note about seal failure, a policy document about pump maintenance, and a contract clause that mentions replacement work.
That is a good start. It is not yet a good answer.
The policy may mention the right product but apply only in another region. The support note may describe the right failure mode but be tied to a retired product version. The contract clause may use similar language but belong to another customer. A retrieved passage can be semantically relevant and still be wrong for this customer, this asset, this contract, this entitlement, this incident date, or this user.
That is the practical gap GraphRAG is meant to close.
GraphRAG is a retrieval-augmented generation pattern that adds graph-based relationship context to semantic retrieval. Instead of sending only similar passages to a model, a GraphRAG system can also retrieve connected entities, relationship paths, structured facts, source identifiers, and provenance.
In this article, Oracle GraphRAG means a GraphRAG-style architecture pattern built with Oracle AI Database 26ai capabilities. It is not a separate product name. The examples use Oracle AI Database 26ai capabilities such as SQL property graphs and Oracle AI Vector Search.
The practical pattern is simple: use vector search to find candidate text, use graph traversal to understand which entities and relationships matter, use SQL predicates to apply structured filters and authorization, and send the AI workflow an evidence bundle rather than a loose pile of similar passages.
For the ACME question, the retrieval layer should be able to answer questions like these before it sends context to a model:
- Does ACME Manufacturing own
PUMP-17? - Which product is
PUMP-17an instance of? - Which contract is active for ACME?
- Which entitlement does that contract grant?
- Does the entitlement cover Pump X9?
- Which policy governs Pump X9 in EMEA on the incident date?
- Which support document cites the policy?
- Is the requesting user allowed to see this contract, policy, asset, and document context?
That is the shift. We are not just looking for text about seal failure. We are looking for evidence that applies.
Where this article fits in the graph series
This article builds on a few recent RedStack posts about graph features in Oracle AI Database 26ai. If you want the hands-on starting point, begin with Build your first SQL property graph in Oracle AI Database 26ai. That post shows the basic shape of creating and querying a graph.
The follow-up, From graph patterns to analytics and visualization, moves from simple pattern matching into more useful graph work. Then Implementing GraphRAG with Oracle AI Database 26ai: SQL Property Graphs, Vector Search, and Automated Graph Extraction looks directly at the GraphRAG shape.
The previous RedStack piece, From GraphRAG Demo to AI System: Build a Minimum Viable Knowledge Graph with Oracle AI Database 26ai, introduced the idea that we should not start by modeling the whole enterprise. Here, we will stay close to the developer problem: how to turn a promising GraphRAG demo into a small retrieval pattern that can become part of a real enterprise AI system.
The ACME/PUMP-17 example below is a fictional product-support scenario used to illustrate the architecture pattern.
Why vector similarity is not always applicable evidence
Vector search is valuable because language is messy. Users rarely ask questions using the exact words in your documents. A support engineer may ask about “pump 17,” while the manual says “Pump X9 installed asset,” the policy says “sealed pump assembly,” and the case note says “mechanical seal failure.”
Oracle AI Vector Search helps with that semantic gap. It lets applications store vector embeddings with business data and query for semantic similarity. That is a strong starting point for retrieval-augmented generation.
The hard part begins when similar text has to be tested against business context. Similarity helps find candidate evidence. It does not prove that the evidence applies.
For our support example, a policy passage may be highly similar to the question. It may mention Pump X9 and seal failure. But the answer can still be wrong if ACME does not have the right entitlement, the contract is inactive, the policy applies only outside EMEA, the policy was not effective on the incident date, or the user cannot access the contract details.
That is why the retrieval path needs relationships among customers, assets, products, contracts, entitlements, policies, regions, dates, support documents, and incidents.
Those relationships are often already present in operational systems. They appear as foreign keys, relationship tables, status columns, date ranges, document metadata, entitlement rules, and access predicates. A knowledge graph becomes useful when it makes those relationships retrievable for the AI workflow.
A knowledge graph represents important business entities and the relationships among them. In enterprise AI, that graph might connect customers to contracts, assets to products, policies to regions, suppliers to components, employees to certifications, or incidents to affected services.
The graph is not valuable because it is abstract. It is valuable because the relationships change which evidence should be retrieved, how the answer should be explained, or what the workflow should do next.
There is a boundary worth stating plainly. Graph context supports retrieval and explanation. It does not replace business rules, data quality work, authorization, review workflows, or application-level evaluation. If a policy decision requires approval, the graph should help assemble evidence for that decision. It should not pretend to be the decision-maker.
The same pattern shows up outside product support. In supplier risk, the answer may depend on suppliers, facilities, contracts, certifications, incidents, components, and affected products. In policy compliance, it may depend on regulations, controls, policies, exceptions, evidence documents, and business units. In workforce planning, it may depend on employees, roles, certifications, projects, skills, and learning material.
Graph-enriched retrieval is useful when relationships change which evidence is applicable, how the answer is explained, or what action the workflow should take next.
What is a minimum viable knowledge graph?
A minimum viable knowledge graph is the smallest set of entities, relationships, and linked sources that improves one real AI retrieval workflow. It is not an enterprise-wide ontology. It starts with one use case, one domain, and the relationships that change whether an answer is correct, applicable, or explainable.
That definition matters because graph projects are easy to overbuild. Once you start drawing entities and relationships, everything feels connected to everything else. Customers connect to accounts, accounts connect to contracts, contracts connect to products, products connect to suppliers, suppliers connect to facilities, facilities connect to shipments, and suddenly your “first graph” has become a long-running modeling program.
Start smaller.
The first graph should earn the right to grow. Start with the path that makes one answer better.
For the support scenario, the first graph might contain customer, asset, product, contract, entitlement, policy, and support document entities. The first relationships might be just as small: customer owns asset, asset is an instance of product, customer has contract, contract grants entitlement, entitlement covers product, policy governs product, and support document cites policy.
That is enough to test whether a policy applies to a customer asset. It is also small enough for a development team to reason about.
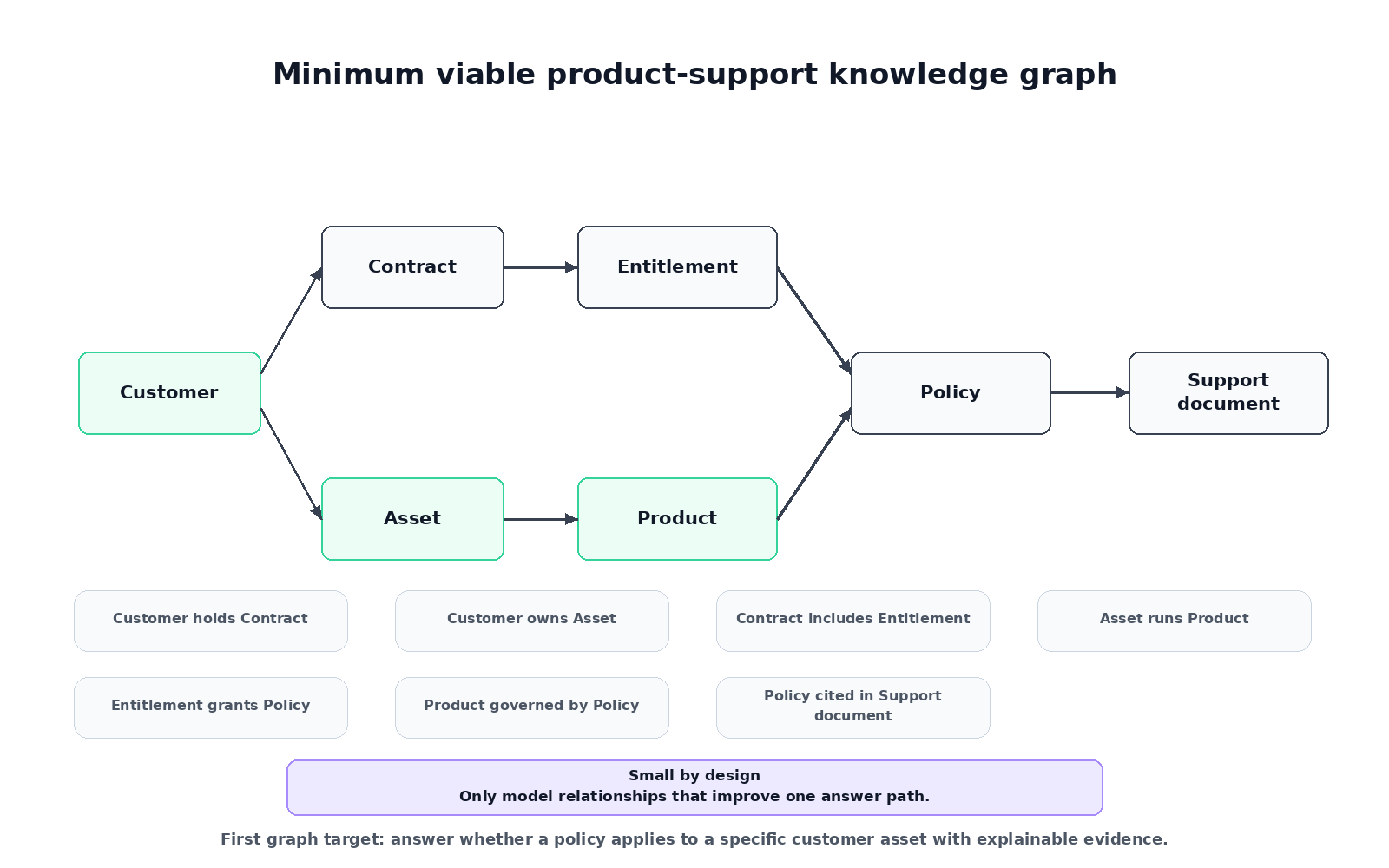
Figure 2. A minimum viable knowledge graph starts with the relationships that change answer quality for one use case.
The practical test for each relationship is simple:
Would this relationship change which evidence we retrieve, how we rank it, or how we explain the answer?
If the answer is no, it can probably wait.
A good first graph has one domain, one AI use case, a small set of entity types, a small set of relationship types, a few trusted documents or records, a measurable retrieval question, and a way to compare results against known answers.
Product support is a good starter domain because support questions often depend on customer assets, product versions, contracts, entitlements, policies, and support documents. Policy compliance, supplier risk, asset maintenance, customer service, and workforce skills can also work well.
The point is not to avoid ambition. The point is to make progress. You can add suppliers, facilities, incidents, exceptions, regulatory controls, service history, and case outcomes later. Add them when a real retrieval failure shows that the graph is missing something.
How Oracle AI Database 26ai capabilities map to GraphRAG
Oracle AI Database 26ai can support this pattern because graph, vector, relational, JSON, and SQL capabilities can be used together in a database-centered architecture. That does not mean the database automatically builds the GraphRAG application. It means developers have a practical foundation for keeping retrieval close to the business data that gives evidence its meaning.
A SQL property graph exposes selected database objects as vertices and edges with labels and properties, so applications can query relationship patterns while still working inside a SQL-centered database architecture. In Oracle AI Database 26ai, CREATE PROPERTY GRAPH defines a property graph over supported database objects, and GRAPH_TABLE can match graph patterns and project results as rows and columns.
For the support workflow, the graph can expose customers, assets, products, contracts, entitlements, policies, support documents, and incidents. The graph query retrieves the path that explains applicability: ACME owns PUMP-17; PUMP-17 is an instance of Pump X9; ACME has an active contract; the contract grants Premium maintenance; Premium maintenance covers Pump X9; and the policy governs Pump X9 in EMEA on the incident date.
Oracle AI Vector Search does a different job. It provides vector storage and similarity search capabilities in Oracle AI Database 26ai, allowing applications to retrieve semantically similar passages, documents, notes, or entity summaries where embeddings have been stored and indexed for retrieval. In this workflow, vector search might retrieve policy chunks, support document chunks, product manual excerpts, case notes, contract clause summaries, or entity summaries about seal failure.
Relational tables remain central. They hold operational facts such as customer records, contract status, asset inventory, product versions, policy effective dates, tenancy, and approval state. SQL is the control plane for applicability: region, date, status, tenant scope, product lifecycle state, data classification, user access predicates, and business rules.
JSON is useful where flexible metadata helps. A document chunk may carry JSON metadata for page number, section title, source system, extraction confidence, classifier output, or retrieval trace. An application may serialize an evidence bundle as JSON before sending it to an LLM or another service. Oracle AI Database 26ai supports JSON data management alongside relational data, which is useful when metadata changes faster than the core operational schema.
Security has to travel with the retrieval path. If the user cannot access a contract, policy, support case, document chunk, graph path, or structured fact, that item should stay out of retrieval results, evidence bundles, prompts, logs, traces, and responses.
Database-layer controls such as privileges and row-level predicates can help, and the Oracle AI Database Security Guide covers the broader database security model. The application still has to pass user context, call the right retrieval service, apply authorization-aware predicates, and avoid leaking restricted context into prompts, logs, traces, or responses.
The architecture boundary is important. Oracle AI Database 26ai provides the graph, vector, relational, JSON, and SQL foundation. The application or retrieval service orchestrates entity resolution, embedding calls or lookup, graph traversal, result fusion, prompt assembly, response handling, evaluation, and workflow-specific approval logic.
A practical Oracle GraphRAG flow
A practical Oracle GraphRAG flow turns a user question into an evidence bundle. The retrieval service does the orchestration, while Oracle AI Database 26ai capabilities provide graph, vector, relational, JSON, and SQL context for the bundle.

Figure 1. The application or retrieval service orchestrates the GraphRAG flow. Oracle AI Database 26ai supplies graph, vector, relational, JSON, and SQL capabilities used to assemble the evidence bundle.
In a typical flow:
- The application captures the user question, identity, tenant or customer context, and any known entities from the UI.
- The application embeds or interprets the question.
- Oracle AI Vector Search retrieves candidate passages, chunks, records, or summaries.
- The application resolves relevant entities such as customer, asset, product, policy, contract, incident, or region.
- A SQL property graph query traverses relationships among those entities.
- SQL predicates apply region, date, status, entitlement, tenant, data classification, and authorization-aware filters.
- The retrieval service assembles an evidence bundle with passages, graph paths, structured facts, source identifiers, and provenance.
- The evidence bundle is sent to an LLM, assistant, search workflow, recommendation service, decision-support UI, or bounded agent.
- The application returns an answer, recommendation, or next action with source references and workflow controls.
An evidence bundle is the context assembled for an AI workflow. It gives an LLM, assistant, search application, recommendation service, decision-support workflow, or agent a grounded basis for an answer or next action.
That “grounded basis” wording is intentional. The evidence bundle is not a guarantee that the generated answer is correct. It is a better input to the workflow. The application still needs evaluation, response controls, user experience design, and human review where the domain requires it.
Walkthrough: policy context for a customer asset
Let’s make the pattern concrete with a small fictional product-support slice. This is a walkthrough, not a full copy-paste tutorial. The important part is the retrieval shape: the graph retrieves the applicability path, while vector search retrieves semantically relevant passages that the application can filter against that path.
Here is the data slice:
Customer: ACME ManufacturingCustomer key: acme-mfgPolicy-applicability region: EMEAAsset: PUMP-17Product: Pump X9Contract: ACME-2026-PLATINUMContract status: ACTIVEEntitlement: Premium maintenancePolicy: Pump X9 Seal Failure PolicyPolicy code: pump-x9-seal-failure-emeaIncident type: seal_failureSupport doc: Pump X9 Maintenance GuideDocument code: pump-x9-maint-guideEvent date: 2026-03-14
A vector search for the engineer’s question may retrieve passages about pump seals, maintenance procedures, and policy language. The graph’s job is narrower. It should retrieve the path that proves which policy is applicable to this customer asset.
In plain text, the useful path looks like this:
ACME Manufacturing owns PUMP-17 is an instance of Pump X9ACME Manufacturing has ACME-2026-PLATINUM grants Premium maintenance covers Pump X9Pump X9 is governed by Pump X9 Seal Failure Policy applies in EMEA applies to seal_failure is cited by Pump X9 Maintenance Guide
A SQL property graph query can make that path retrievable once the underlying graph, labels, edge definitions, properties, and predicates are defined.
For this simplified walkthrough, the customer’s region is the policy-applicability region. In a production support system, that predicate might use the asset install site, service territory, contract region, or incident location instead.
The following block is SQL/PGQ-style pseudocode, not a complete runnable script. It is meant to show the relationships and predicates that belong in the retrieval path. A runnable version would require tested table definitions, sample data, privileges, a CREATE PROPERTY GRAPH statement, and target-environment syntax.
SELECT customer_name, asset_tag, product_name, contract_number, entitlement_name, policy_code, policy_title, policy_region, effective_from, source_code, source_titleFROM GRAPH_TABLE ( support_graph MATCH (c IS customer)-[IS owns]->(a IS asset) -[IS instance_of]->(p IS product), (c)-[IS has_contract]->(ct IS contract) -[IS grants]->(e IS entitlement) -[IS covers]->(p), (pol IS policy)-[IS governs]->(p), (doc IS support_document)-[IS cites]->(pol) WHERE c.customer_key = 'acme-mfg' AND a.asset_tag = 'PUMP-17' AND ct.status = 'ACTIVE' AND pol.region = c.region AND pol.incident_type = 'seal_failure' AND pol.effective_from <= DATE '2026-03-14' AND (pol.effective_to IS NULL OR pol.effective_to >= DATE '2026-03-14') COLUMNS ( c.name AS customer_name, a.asset_tag AS asset_tag, p.product_name AS product_name, ct.contract_number AS contract_number, e.entitlement_name AS entitlement_name, pol.policy_code AS policy_code, pol.title AS policy_title, pol.region AS policy_region, pol.effective_from AS effective_from, doc.source_code AS source_code, doc.title AS source_title ));
The authorization checks are intentionally shown as architecture requirements rather than runnable SQL. Do not send a graph path, document chunk, or structured fact to the model unless the requesting user is allowed to see it.
A conceptual result from that traversal would identify:
- Customer: ACME Manufacturing
- Asset:
PUMP-17 - Product: Pump X9
- Contract:
ACME-2026-PLATINUM - Entitlement: Premium maintenance
- Policy: Pump X9 Seal Failure Policy
- Policy code:
pump-x9-seal-failure-emea - Policy region: EMEA
- Effective from: 2026-01-01
- Source document: Pump X9 Maintenance Guide
- Source code:
pump-x9-maint-guide
This result gives the AI workflow something more useful than a similar passage. It gives the path that explains applicability:
Pump X9 Seal Failure Policy applies to ACME Manufacturing's PUMP-17because ACME owns the asset, the asset is an instance of Pump X9,ACME has an active premium maintenance contract, the entitlement coversPump X9, the policy governs Pump X9 in EMEA for seal failure, and themaintenance guide cites the policy.
Now vector search can plug in cleanly. Oracle AI Vector Search can retrieve passages about seal failure from policy chunks, support documents, or product manuals where those passages have embeddings available. The graph traversal identifies which policies and products apply to this customer asset. SQL predicates then keep only passages that match the applicable policy, incident type, region, effective date, entitlement, tenant scope, and authorization rules.
Vector search is still doing important work. The graph does not replace semantic retrieval; it helps decide which semantically relevant passages are applicable to this business situation.
The evidence bundle might look like this at the application boundary:
{ "question": "Which maintenance policy applies to ACME's pump 17 after the seal failure?", "entities": { "customer_key": "acme-mfg", "customer_name": "ACME Manufacturing", "asset_tag": "PUMP-17", "product_name": "Pump X9", "region": "EMEA" }, "access_context": { "tenant": "acme-mfg", "requesting_role": "support_engineer", "filtered_before_prompt": true }, "graph_context": [ { "path": "ACME Manufacturing -> PUMP-17 -> Pump X9 -> pump-x9-seal-failure-emea", "reason": "The policy governs the product in the customer's region for the incident date and incident type." }, { "path": "ACME Manufacturing -> ACME-2026-PLATINUM -> Premium maintenance -> Pump X9", "reason": "The active contract grants an entitlement that covers the product." }, { "path": "Pump X9 Maintenance Guide -> pump-x9-seal-failure-emea", "reason": "The support document cites the applicable policy." } ], "passages": [ { "source_code": "pump-x9-maint-guide", "policy_code": "pump-x9-seal-failure-emea", "title": "Pump X9 Maintenance Guide", "section": "Seal failure procedure" } ], "structured_facts": { "contract_status": "ACTIVE", "policy_effective_from": "2026-01-01", "incident_type": "seal_failure", "event_date": "2026-03-14" }, "provenance": [ { "source_code": "pump-x9-maint-guide", "source_type": "support_document", "title": "Pump X9 Maintenance Guide" }, { "source_code": "pump-x9-seal-failure-emea", "source_type": "policy", "title": "Pump X9 Seal Failure Policy" } ]}
This JSON is not a built-in database response. It is an application pattern. The retrieval service decides how to assemble, filter, log, and pass this context to the next consumer.
The access_context field is illustrative. The important point is that authorization filtering happens before the bundle is logged, sent to a model, or returned to a caller.
The walkthrough proves a modest but useful point: a small graph path can retrieve applicability context. It does not build a full LLM app, implement production authorization, solve entity resolution, or evaluate generated answers. That is fine. The first step is to make the relationship retrievable.
Turn graph-enriched retrieval into a knowledge service
The useful boundary is not “the graph.” The useful boundary is a service that returns trusted context for a workflow.
If we bury the graph query inside one chatbot, the pattern will not travel very far. The next search app, agent, recommendation service, or case-management screen will rebuild the same logic. A better design is to expose graph-enriched retrieval as an application knowledge service.
A platform team might expose a bounded service shape like this:
get_policy_context(customer_key, asset_tag, incident_type, event_date)
Behind that boundary, the implementation could use SQL lookups, GRAPH_TABLE, Oracle AI Vector Search, JSON metadata, relational filters, and authorization-aware predicates. The caller should not need to know the graph schema or the vector indexing strategy.
A conceptual request might look like this:
{ "customer_key": "acme-mfg", "asset_tag": "PUMP-17", "incident_type": "seal_failure", "event_date": "2026-03-14"}
And a conceptual response could return the applicable policy, the relationship paths, and the source references:
{ "applicable_policy": { "policy_code": "pump-x9-seal-failure-emea", "title": "Pump X9 Seal Failure Policy", "region": "EMEA", "incident_type": "seal_failure", "effective_from": "2026-01-01" }, "relationship_paths": [ "ACME Manufacturing owns PUMP-17", "PUMP-17 is an instance of Pump X9", "ACME Manufacturing has active contract ACME-2026-PLATINUM", "ACME-2026-PLATINUM grants Premium maintenance", "Premium maintenance covers Pump X9", "Pump X9 Seal Failure Policy governs Pump X9 in EMEA for seal failure", "Pump X9 Maintenance Guide cites Pump X9 Seal Failure Policy" ], "sources": [ { "source_code": "pump-x9-maint-guide", "title": "Pump X9 Maintenance Guide", "section": "Seal failure procedure" } ]}
The service contract is conceptual. It is not a built-in Oracle endpoint; it is an application boundary that hides graph schema, vector indexing strategy, and authorization logic from callers.
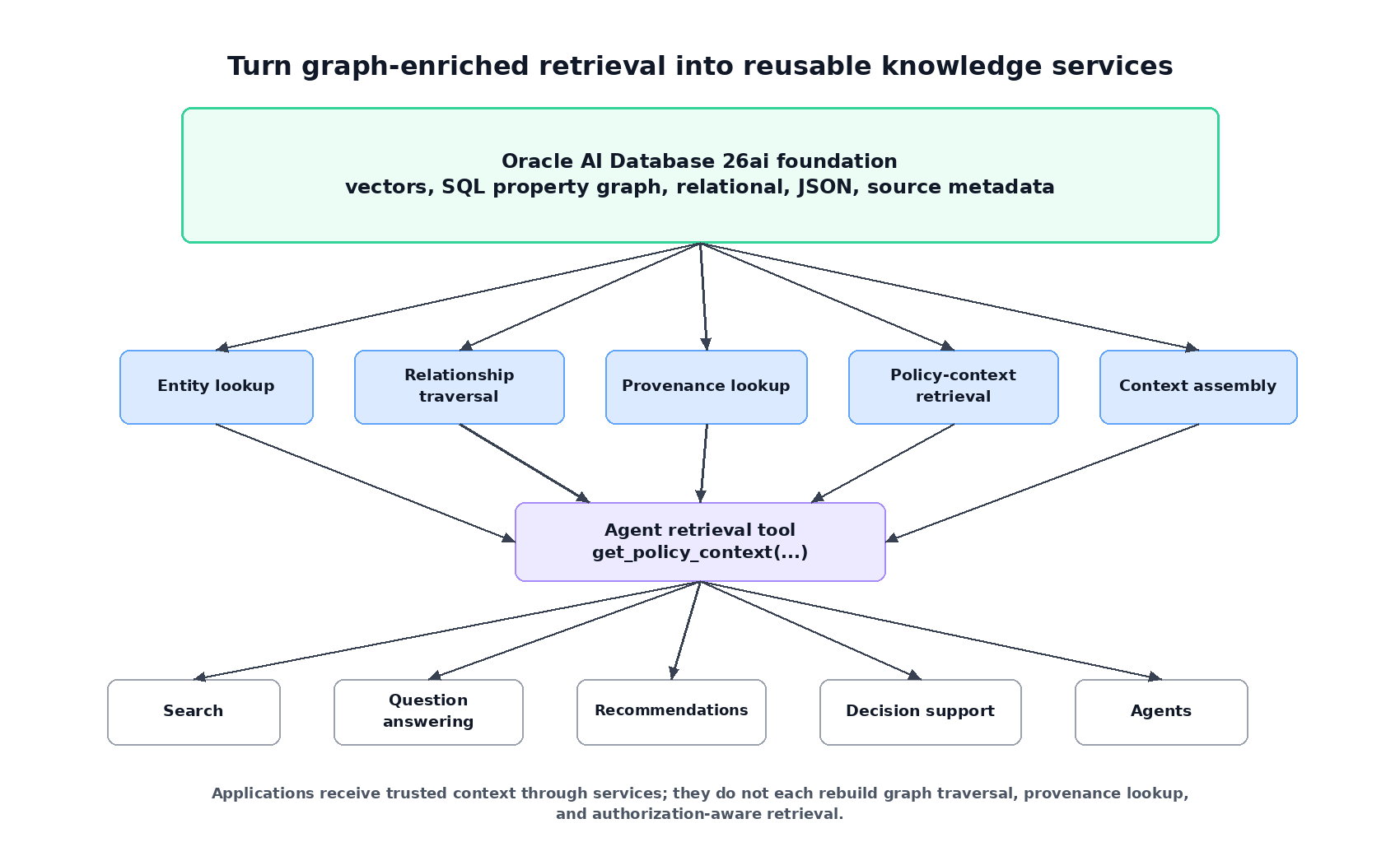
Figure 3. Once the first graph path is useful, expose graph-enriched retrieval as reusable services instead of rebuilding context assembly in every application.
The service layer can start small. Entity lookup resolves user terms to trusted database entities. Relationship traversal returns paths connecting customers, assets, products, contracts, policies, and documents. Policy-context retrieval returns policies applicable to a customer, asset, product, region, date, or incident. Provenance lookup returns source documents, sections, codes, and lineage. Context assembly builds evidence bundles for questions.
An agent retrieval tool is another useful boundary. It gives an agent bounded access to context without giving it raw enterprise data access.
This is where a GraphRAG demo starts to look like a system. The graph is still small, but the boundary is reusable.
Where GraphRAG helps in enterprise AI workflows
Graph-enriched retrieval helps when relationships change which evidence is applicable, how the answer is explained, or what action the workflow should take next.
For semantic search and question answering, a support assistant can retrieve passages about a product failure, then use graph context to check the customer’s asset, contract, entitlement, product, and region. The workflow can return source-backed evidence for the applicable policy instead of a generic policy summary.
For knowledge discovery, a product team can ask which policies, support cases, and incidents are connected to a recurring asset failure. Vector retrieval may find relevant notes. Graph traversal can connect those notes to products, assets, policies, regions, and affected customers.
For recommendations, a service workflow can recommend the next troubleshooting step based on product, asset history, known failure modes, entitlement, and trusted support documents. The recommendation is more useful when the system can explain the path that led to it.
For decision support, a case manager can see why a policy applies before approving an exception. The evidence bundle can show the applicable contract, entitlement, policy, support document, event date, and source references. That does not remove the need for review. It makes the review easier.
For AI agents, the pattern is especially important. An agent should have bounded retrieval tools instead of open-ended access to raw enterprise tables. Give the agent a tool that returns policy context, graph paths, source passages, and provenance. Let the application decide what actions are allowed, what needs approval, and what gets logged.
This pattern is not necessary for every AI system. If a workflow only needs to find a few public documents, vector or hybrid search may be enough. Use GraphRAG when relationship context materially changes retrieval quality or workflow behavior.
What to build next
The next step is not to schedule a six-month ontology program. The next step is to pick one useful workflow and make one relationship path retrievable.
Start with a sequence like this:
- Pick one domain, such as product support, policy compliance, supplier risk, asset maintenance, customer service, or workforce skills.
- Pick one AI use case where users already ask questions today.
- Write five real questions users ask in that workflow.
- Identify the relationships that change the answer.
- Model the smallest useful set of entities and edges.
- Link trusted documents or chunks to graph entities.
- Add vector search where semantic retrieval improves the workflow.
- Use SQL predicates for status, date, region, tenant, entitlement, and authorization.
- Evaluate against known questions and expected evidence.
- Expand only when failures show a missing entity, relationship, source, or filter.
The first evaluation should be practical. Did the system retrieve the right source passages? Did it find the right graph path? Did it apply the right region, date, status, entitlement, tenant, and authorization filters? Did it avoid restricted records? Did it return source references that a human can inspect?
You can also compare the graph-enriched result with a vector-only result. The question is not whether the graph feels more sophisticated. The question is whether it retrieves better evidence for the workflow.
If the system fails because the customer-to-asset relationship is missing, add it. If it fails because policy effective dates are not modeled, add them. If it fails because support documents are not linked to products or policies, add that link. Let failures guide the graph’s growth.
That keeps the graph honest. It grows because it improves retrieval, explanation, recommendation, or decision support.
Conclusion
GraphRAG becomes useful when relationships become retrievable evidence. Similar passages matter, but enterprise AI often needs more: customer context, asset ownership, product identity, active contracts, entitlements, policy scope, region, effective dates, permissions, source references, and provenance.
Oracle AI Database 26ai is a practical foundation for this pattern because SQL property graphs, Oracle AI Vector Search, relational data, JSON metadata, and SQL predicates can work together in a database-centered architecture. The application still orchestrates the workflow, but the retrieval layer can stay close to the governed business data that gives evidence its meaning.
The first project should be small. Build a minimum viable knowledge graph for one workflow. Use vector search to find candidate passages. Use graph traversal and SQL predicates to test applicability. Assemble an evidence bundle that an LLM, assistant, search app, recommendation service, decision-support workflow, or bounded agent can use.
Pick one workflow, find the relationship that changes the answer, and build the smallest graph path that makes that relationship retrievable.

You must be logged in to post a comment.